多年来,研究人员一直在努力快速准确地识别导致癌症等遗传疾病的 DNA 部分。科罗拉多大学博尔德分校的研究人员推出的一种新软件工具可以改善这一过程,并为患者提供更量身定制的治疗和对癌症的了解。
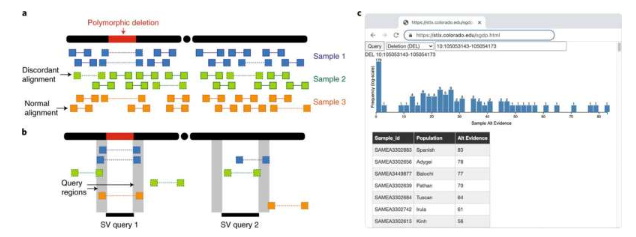
“了解癌症需要确定导致患者健康细胞失控生长的基因变化,”助理教授 Ryan Layer 说。“不幸的是,任何给定的肿瘤都有数千个这样的变化,而且大多数是遗传的——没有突变——或者根本没有影响。为了识别有问题的变异,我们开发了一种技术,可以快速搜索数千个已知基因组集,以确定突变仅在肿瘤中可见。”
这项工作是计算机科学系和 BioFrontiers 研究所内 Layer 实验室正在进行的研究的一部分,该研究使用算法来破译非常大的基因组数据集。这种名为 STIX 的新软件专门研究可能导致癌症的大型结构变异。STIX 使用二次分析技术从数千个样本中搜索原始数据,寻找任何支持每个特定肿瘤中存在变异的证据。
该过程在Nature Methods的一篇新论文中进行了描述,旨在快速表征特定基因序列是常见的还是罕见的,并可能在这些特定的肿瘤细胞中引起癌症等疾病。最终目标是根据患者实际肿瘤与正常组织相比的序列发现,为患者提供更量身定制的治疗。最后,Layer 表示他们希望以一种任何人、任何地方都可以使用的方式提供这些信息。
“隐藏在癌症患者肿瘤基因组中的某处是编码肿瘤如何开始失控生长的指令的突变,”Layer说。“不幸的是,驱动肿瘤的突变与人类发育和功能的所有其他方面的指令混合在一起——使其成为一项复杂而耗时的任务。”
该论文的第一作者、Layer 实验室的一名科学家 Murad Chowdhury 表示,计算一个序列在健康人群中的出现以帮助确定它是否是疾病驱动的突变并不是一个新想法。然而,该团队的方法通过包含大的基因突变来扩展理论,这需要一种根本不同的频率估计方法,因为它们更难检测和表征。
Chowdhury 说,团队面临的主要挑战是计算——获取大型数据集并重新组织它们,只需花费一秒钟的时间在数据中搜索所需的信息。尽管如此,该方法被证明是一种有效的工具,未来可能会应用于医学之外。
Chowdhury 说:“我们的技术同时减少了数据存储需求并提高了查询速度,因此需要数月才能完成的分析可以更快地进行。”“通过结合机器学习,您基本上可以将这种背景分布用于癌症以外的许多潜在的未来应用。”
莱尔说,研究人员每年都会做很多工作来分析和分类有关肿瘤的信息。他的实验室使用此类工具的最终目标是使这项投资变得有价值和有用。
标签:
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!