通过将无监督和自动化机器学习技术应用于数百万癌细胞的分析,Rebecca Ihrie 和 Jonathan Irish 都是细胞和发育生物学副教授,他们在脑肿瘤中发现了新的癌细胞类型。机器学习是一系列计算机算法,可以识别大量数据中的模式,并通过更多经验变得“更聪明”。这一发现有望使研究人员能够更好地理解和靶向这些细胞类型,用于胶质母细胞瘤(一种高死亡率的侵袭性脑肿瘤)的研究和治疗,以及机器学习在癌症研究中的更广泛适用性。
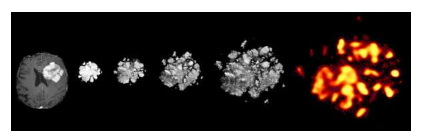
Ihrie 和 Irish 与其合作者一起开发了风险评估群体识别 (RAPID),这是一种开源机器学习算法,可揭示与生存结果相关的蛋白质表达和修饰的协调模式。
文章“Unsupervised machine learning reveals risk stratifying glioblastoma tumor cells”于 6 月 23 日在线发表在eLife杂志上。RAPID 代码和示例可在 cytolab Github 页面上找到。
在过去的十年中,研究界一直致力于利用机器学习的能力来吸收和分析比人类思维单独处理的更多的癌细胞研究数据。“在没有任何人为监督的情况下,RAPID 梳理了 200 万个肿瘤细胞——每个患者至少有 4,710 个胶质母细胞瘤细胞——来自 28 个胶质母细胞瘤,标记出最不寻常的细胞和模式供我们研究,”Ihrie 说。“我们能够在大海捞针中找到针头,而无需搜索整个大海捞针。这项技术让我们能够专注于更好地了解最危险的癌细胞,并更接近于最终治愈脑癌。”
将控制神经干细胞和其他脑细胞的身份和功能的细胞蛋白质数据输入 RAPID。使用的数据类型称为单细胞质谱流式细胞术,这是一种通常应用于血癌的测量技术。一旦 RAPID 的统计分析完成并找到了“大海捞针”,就只会研究那些细胞。“我们研究中最令人兴奋的结果之一是,无监督机器学习发现了最严重的罪犯细胞,而不需要研究人员为其提供临床或生物学知识作为背景,”Irish 说,他也是范德比尔特大学癌症与免疫学核心的科学主任。“这项研究的结果目前代表了我在范德比尔特实验室的最大生物学进展。”
研究人员的机器学习分析使他们的团队能够研究脑肿瘤细胞中蛋白质的多种特征与其他特征的关系,从而提供新的和意想不到的模式。“我们两个实验室之间的合作,我们从范德比尔特大学和范德比尔特-英格拉姆癌症中心 (VICC) 获得的这项高风险工作的支持,以及与神经外科医生和病理学家的卓有成效的合作,他们为研究人类细胞提供了独特的机会Ihrie 和 Irish 在一份联合声明中说:“直接从大脑中取出让我们实现了这一里程碑。” 该论文的共同第一作者是前范德比尔特大学研究生 Nalin Leelatian,目前是耶鲁大学(爱尔兰实验室)的神经病理学住院医师,以及Justine Sinnaeve(Ihrie 实验室)。通过她在该主题上的研究和工作,Leelatian 于 2017 年 4 月获得了美国癌症研究协会 (AACR) 的美国脑肿瘤协会 (ABTA) 培训学者奖。
标签:
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!