深度学习是人工智能的一种形式,它通过教导计算机使用模仿人脑的人工神经网络来处理信息,从而改变社会。它现在被用于面部识别、自动驾驶汽车,甚至用于玩围棋等复杂游戏。一般来说,深度学习的成功取决于使用大型标记图像数据集进行训练。
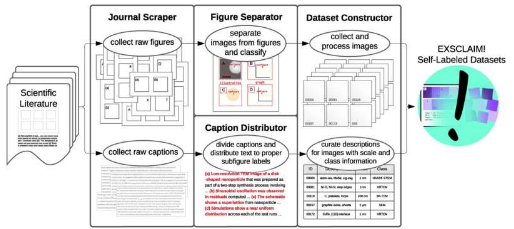
科学文献中蕴藏着潜在的标记图像金矿,每年发表超过一百万篇文章。大多数文本中都融入了许多图形。迄今为止,这些数字尚不适合深度学习模型。这在一定程度上是由于其复杂的布局造成的。每个图形通常包含多个嵌入的图像、图表和插图。还缺乏在文献中搜索与特定内容匹配的图像的适当方法。
为了应对这一挑战,美国能源部 (DOE) 阿贡国家实验室和西北大学的研究人员创建了 EXSCLAIM!软件工具。该名称代表图像的提取、分离和基于标题的自然语言注释。
研究结果发表在《模式》杂志上。
“电子显微镜产生的十亿分之一米的图像是材料科学文献中最重要的图像之一,”阿贡纳米材料中心(美国能源部科学办公室用户设施)的科学家玛丽亚·陈(Maria Chan)说。 “这些图像对于理解和开发许多不同领域的新材料至关重要。我们 EXSCLAIM! 的目标是释放这些成像数据的未开发潜力。”
什么设置 EXSCLAIM!其独特之处在于它对数据集查询方法的独特关注,类似于 ChatGPT 和 DALL-E 等生成式 AI 工具中提示的使用方式。因此,它能够从图形中提取具有非常具体内容的单个图像,因为它既可以对图像内容进行分类,又可以识别放大程度。然后它可以为每个图像创建描述性标签。这种创新的软件工具有望成为研究纳米级新材料的科学家的宝贵资产。
“虽然现有的方法常常难以解决复合布局问题,但 EXSCLAIM! 采用了一种新方法来克服这个问题,”主要作者、前阿贡国家实验室研究生 Eric Schwenker 说。 “我们的软件能够有效识别清晰的图像边界,并且擅长捕捉不规则的图像排列。”
标签:
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!