威尔康奈尔医学院、康奈尔理工学院和康奈尔大学伊萨卡校区的研究人员已经展示了使用人工智能选择的自然图像和人工智能生成的合成图像作为神经科学工具来探测大脑的视觉处理区域。目标是应用数据驱动的方法来理解视觉是如何组织的,同时潜在地消除在查看对研究人员选择的一组更有限的图像的响应时可能出现的偏差。
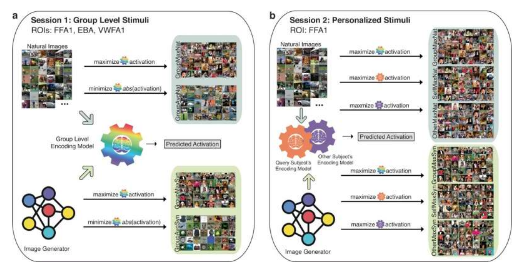
在发表在《通讯生物学》上的这项研究中,研究人员让志愿者查看根据人类视觉系统的人工智能模型选择或生成的图像。预计这些图像将最大程度地激活多个视觉处理区域。研究人员利用功能磁共振成像(fMRI)记录志愿者的大脑活动,发现这些图像确实比对照图像更好地激活了目标区域。
研究人员还表明,他们可以使用这些图像响应数据来调整个体志愿者的视觉模型,以便为特定个体生成最大程度激活的图像比基于通用模型生成的图像效果更好。
“我们认为这是研究视觉神经科学的一种有前途的新方法,”该研究的资深作者、威尔康奈尔医学院菲尔家族大脑和心智研究所的放射学数学和神经科学数学教授 Amy Kuceyeski 博士说。 。
这项研究是与康奈尔工程学院和康奈尔理工学院电气和计算机工程教授以及威尔康奈尔医学院放射学电气工程教授 Mert Sabuncu 博士的实验室合作进行的。该研究的第一作者是 Zijin Gu 博士,他是一名博士生,在研究时由 Sabuncu 博士和 Kuceyeski 博士共同指导。
通过将大脑反应映射到特定图像来建立人类视觉系统的准确模型,是现代神经科学更雄心勃勃的目标之一。例如,研究人员发现,一个视觉处理区域可能会对面部图像做出强烈反应,而另一个视觉处理区域可能会对风景做出反应。考虑到用植入电极直接记录大脑活动的风险和困难,科学家必须主要依靠非侵入性方法来实现这一目标。
首选的非侵入性方法是功能磁共振成像(fMRI),它本质上是记录大脑小血管中血流的变化——这是大脑活动的间接测量——当受试者受到感官刺激或以其他方式执行认知或身体任务时。功能磁共振成像机器可以以立方毫米量级的分辨率读出大脑三个维度的微小变化。
标签:
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!