在过去几年中,可以自主生成各种类型内容的基于机器学习的模型变得越来越先进。这些框架为制作和编译数据集来训练机器人算法开辟了新的可能性。
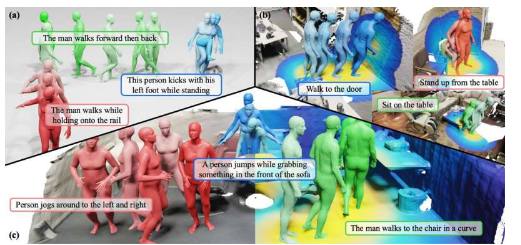
虽然一些现有模型可以根据文本描述生成逼真或艺术图像,但迄今为止,开发能够根据人类指令生成移动人物视频的人工智能更具挑战性。在预先发布在服务器arXiv上并在 IEEE/CVF 计算机视觉与模式识别会议 2024 上发表的论文中,北京理工大学、BIGAI 和北京大学的研究人员介绍了一种有前途的新框架,可以有效地解决这一任务。
“我们之前的工作《HUMANIZE》中的早期实验表明,通过将任务分解为场景基础和条件动作生成,两阶段框架可以增强 3D 场景中语言引导的人体动作生成,”该论文的合著者 Yixin Zhu 说。论文,告诉 Tech Xplore。
“机器人领域的一些工作也证明了可供性对模型泛化能力的积极影响,这激励我们采用场景可供性作为这项复杂任务的中间表示。”
朱和他的同事推出的新框架建立在他们几年前推出的生成模型之上,称为 HUMANIZE。研究人员着手提高该模型泛化新问题的能力,例如在学习有效生成“躺在床上”动作后,创建逼真的动作来响应“躺在地板上”的提示。
“我们的方法分两个阶段展开:用于功能可供性图预测的功能可供性扩散模型 (ADM) 和用于根据描述和预生成的功能可供性生成人体运动的可供性到运动扩散模型 (AMDM),”Siyuan Huang 联合研究人员说道。论文作者解释说。
“通过利用从人体骨骼关节和场景表面之间的距离场导出的可供性图,我们的模型有效地将 3D 场景基础和该任务中固有的条件运动生成联系起来。”
标签:
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!